- Cách truyền thống để thể hiện 1 từ là dùng one-hot vector.

- Độ lớn vector đúng bằng số lượng từ vựng.
- Vấn đề là làm thế nào để thể hiện mối quan hệ giữa các từ, tính tương đồng thế nào. Word2vec là giải pháp cho vấn đề này.
- Có 2 mô hình Word2vec được áp dụng: Skip-gram, Continuous Bag of Words (CBOW)
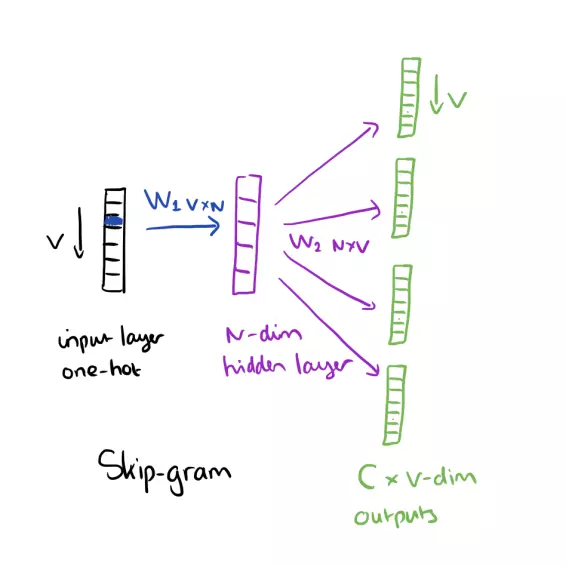
- Skip-gram
Input là từ cần tìm mối quan hệ, output là từ các từ có quan hệ gần nhất với từ đó.
Ví dụ câu: "I have a cute dog", input từ "a", output là “I”, “have”, “cute”, “dog”. 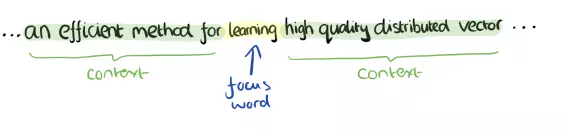
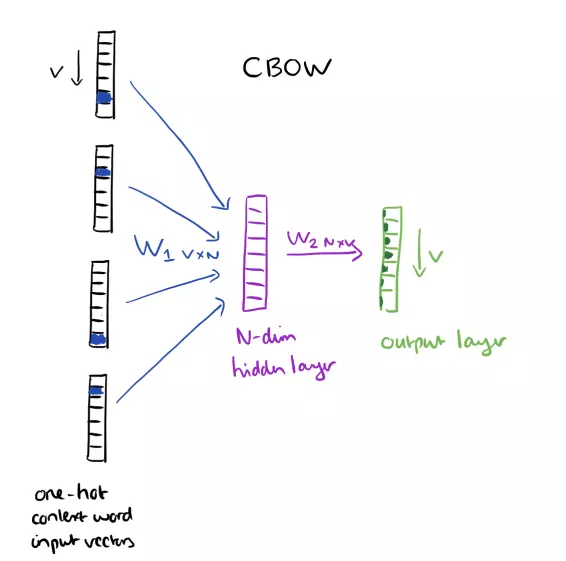
- Continuous Bag of Words
CBOW thì ngược lại, input context, output là từ gần nhất với contenxt đó.
- Mô hình tranning:
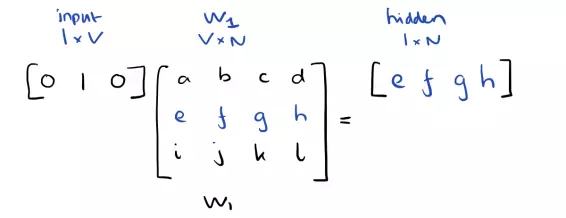
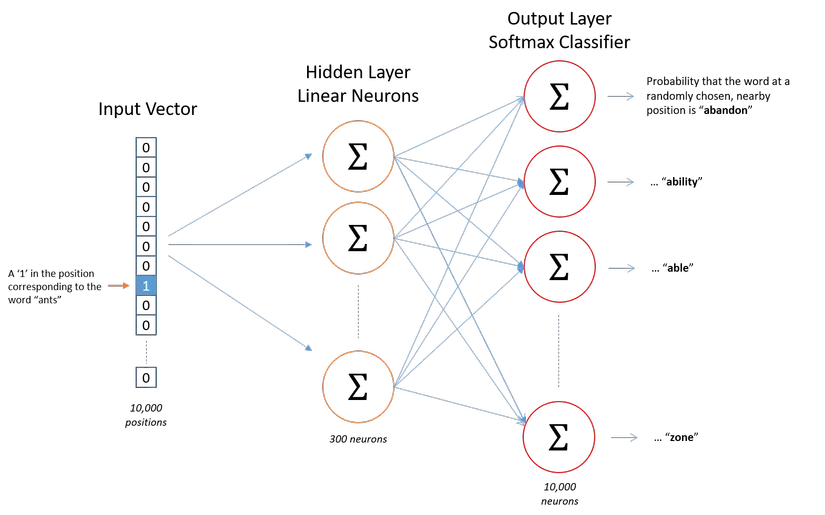
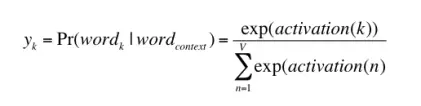
- Cách tính toán cơ bản:
- Tính sigmoid probability
import math
z = [1.0, 2.0, 3.0, 4.0, 1.0, 2.0, 3.0]
z_exp = [math.exp(i) for i in z]
print([round(i, 2) for i in z_exp])
[2.72, 7.39, 20.09, 54.6, 2.72, 7.39, 20.09]
sum_z_exp = sum(z_exp)
print(round(sum_z_exp, 2))
114.98
softmax = [i / sum_z_exp for i in z_exp]
print([round(i, 3) for i in softmax])
[0.024, 0.064, 0.175, 0.475, 0.024, 0.064, 0.175]
- Ví dụ dùng Numpy:
import numpy as np
z = [1.0, 2.0, 3.0, 4.0, 1.0, 2.0, 3.0]
softmax = np.exp(z)/np.sum(np.exp(z))
softmax
array([0.02364054, 0.06426166, 0.1746813 , 0.474833 , 0.02364054, 0.06426166, 0.1746813 ])
- Dự đoán probability của từ:
- Dùng gensim cho word2vec:
num_features = 300 # Word vector dimensionality
min_word_count = 2 # Minimum word count
num_workers = 4 # Number of parallel threads
context = 10 # Context window size
downsampling = 1e-3 # (0.001) Downsample setting for frequent words
# Initializing the train model
from gensim.models import word2vec
print("Training model....", len(sentences))
model = word2vec.Word2Vec(sentences,\
workers=num_workers,\
size=num_features,\
min_count=min_word_count,\
window=context,
sample=downsampling)
# To make the model memory efficient
model.init_sims(replace=True)
# Saving the model for later use. Can be loaded using Word2Vec.load()
model_name = "300features_40minwords_10context"
model.save(model_name)
model.wv.most_similar("awful")
[('also', 0.5430739521980286),
('of', 0.5334444046020508),
('that', 0.5331112742424011),
('with', 0.5315108299255371),
('s', 0.5286026000976562),
('it', 0.5267502069473267),
('be', 0.5258522033691406),
('but', 0.5237830877304077),
('time', 0.5198161602020264),
('way', 0.5197839140892029)]
- Một nhược điểm lớn, là nó không detect được những từ không có trong traning dataset, để khắc phục được điều này chúng ta có FastText là mở rộng của Word2Vec, được suggest bởi facebook năm 2016. Thay thế cho đơn vị word, nó chia text ra làm nhiều đoạn nhỏ, ví dụ apple sẽ thành app, ppl, and ple, vector của từ apple sẽ bằng tổng của tất cả cái này.
- Cảm ơn các bạn đã theo dõi.

- Tham khảo:
Không có nhận xét nào:
Đăng nhận xét