NMF chuyển một matrix X thành phép nhân 2 maxtrix cấp thấp hơn với độ xấp xỉ và sai số nhỏ. Mục đích để giảm cho việc lưu trữ và việc tính toán nhưng vẫn đảm bảo được các đặc điểm của dữ liệu (các đặc tính của mô hình).

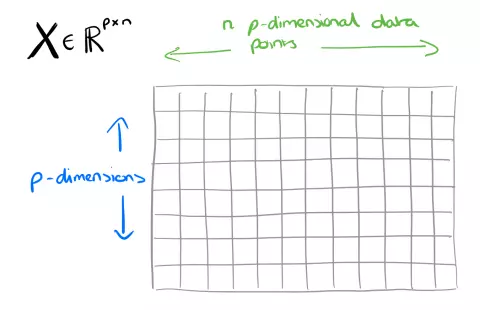
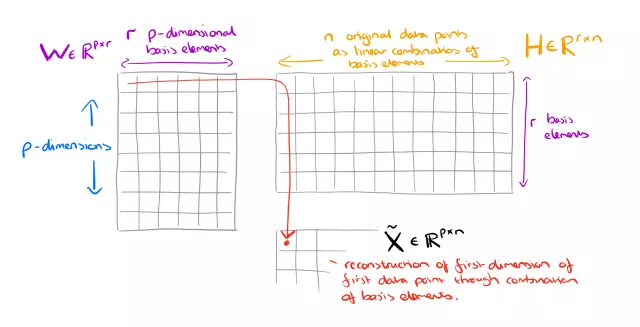
Như trên, chúng ta có một ma trận dữ liệu X (p x n), mục đích của NMF là giảm chiều dữ liệu từ p xuống r thông qua việc tìm 2 ma trận con có phép nhân ~= X Để làm được vậy chúng ta thông qua việc
- random dữ liệu ban đầu.
- So sánh các dữ liệu sinh ra với ma trận kết quả X.
- điều chỉnh lại các thông số cho hợp lí => để tối ưu hàm lỗi (error function).
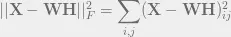
- lặp lại các bước trên cho đến khi lỗi đủ nhỏ (đủ tốt)
Ví dụ. (ứng dụng trong việc dự đoán phìm của netflix bình chọn của NMF):
Chúng ta có 4 người, với 2 thể loại phim là "comedy" và "action", ma trận X tương đương với ma trận lớn, các con số là số điểm rating bộ phim) ma trận "trái" "trên" tương đương với các ma trận cần tìm (phân tách).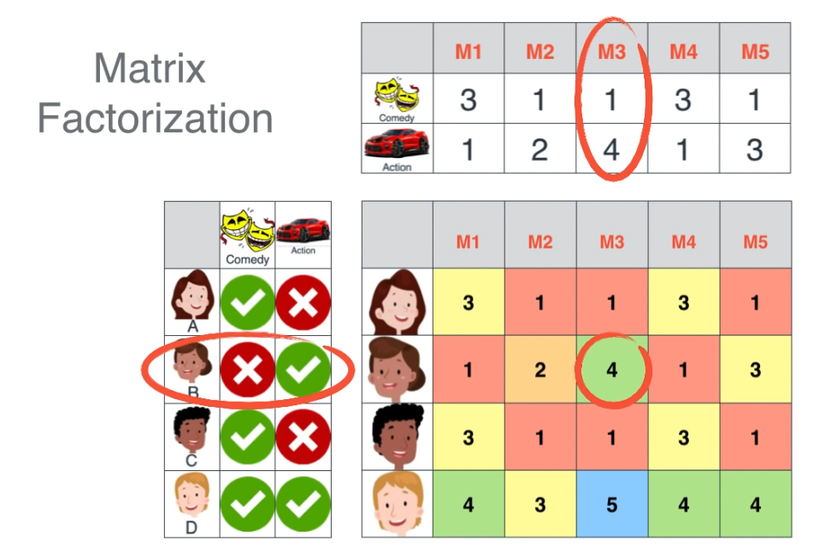
Như bạn thấy, với ma trận lớn ta cần 2 triệu entries để lưu trữ, trong khi việc phân tách ra 2 ma trận sẽ chỉ tốn 300.000 entries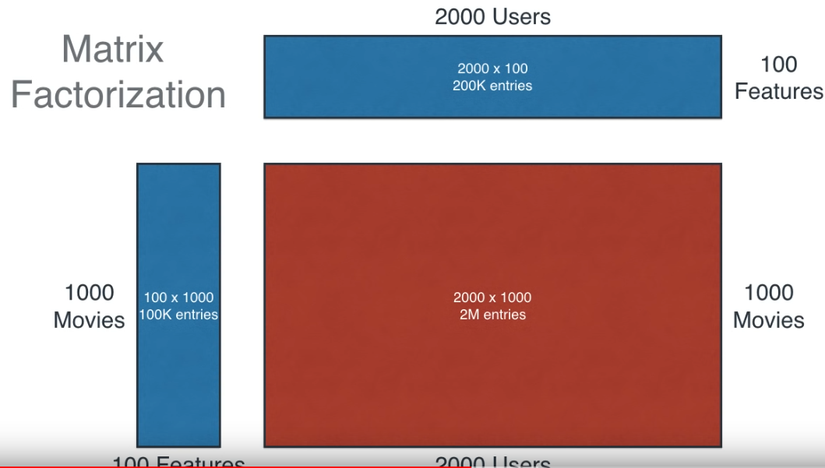
Để tìm được 2 ma trận này ta random các giá trị khởi tạo, tính toán và so sánh với ma trận gốc.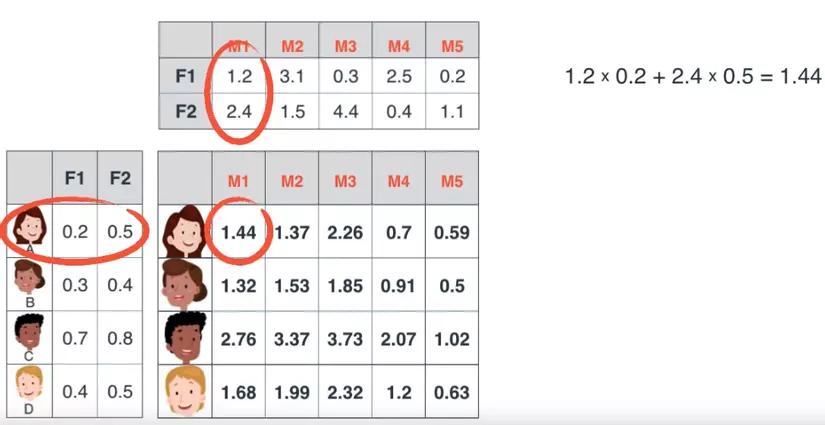
1.44 là nhỏ hơn 3, nên ta cần nâng các param lên.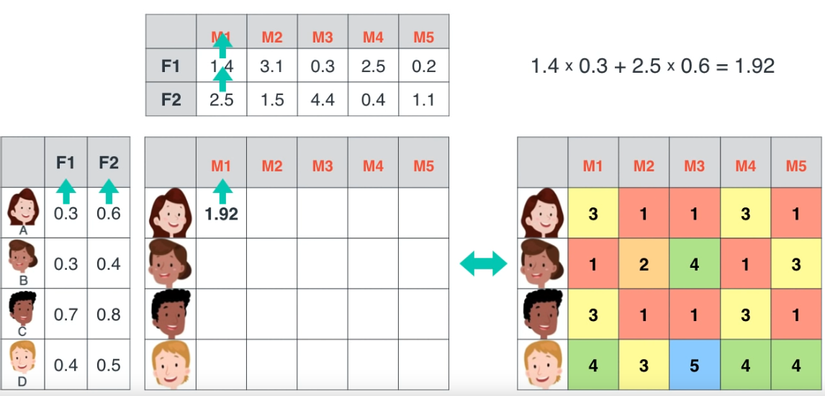
Hoặc giảm xuống (như đối với giá trị tiếp theo).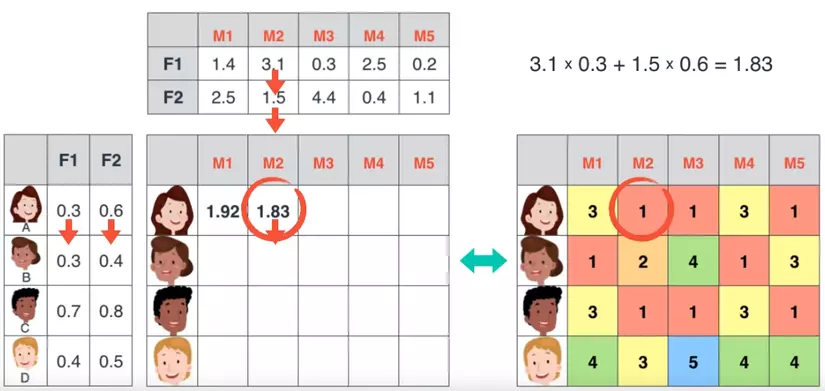
Error function sẽ bằng tổng bình phương chênh lệch, đạo hàm của nó chính là cái chúng ta cần tối ưu.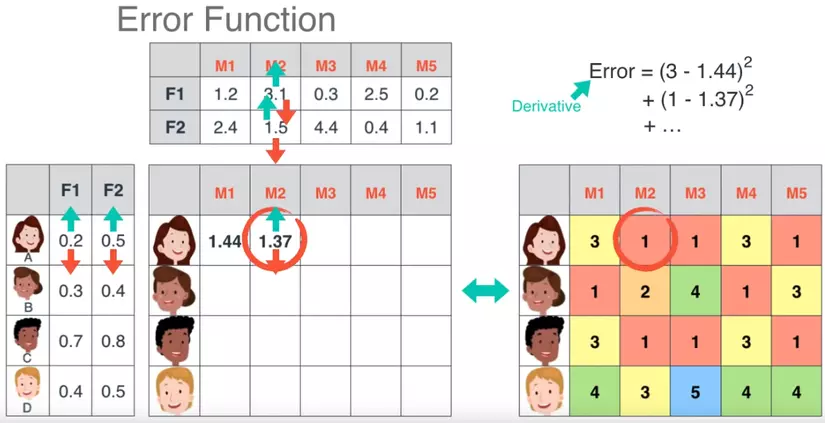
Sau khi tìm được 2 ma trận tương ứng, chúng ta có thể dự đoán được những điểm dữ liệu bị thiếu dựa vào việc nhân ma trận (vì dữ liệu thực tế thường không đầy đủ, rời rạc, chúng ta có thể filling các giá trị giả định, sau khi tìm được các ma trận phù hơp, chúng ta có thể quay lại dùng phép nhân ma trận để dự đoán các dữ liệu bị thiếu).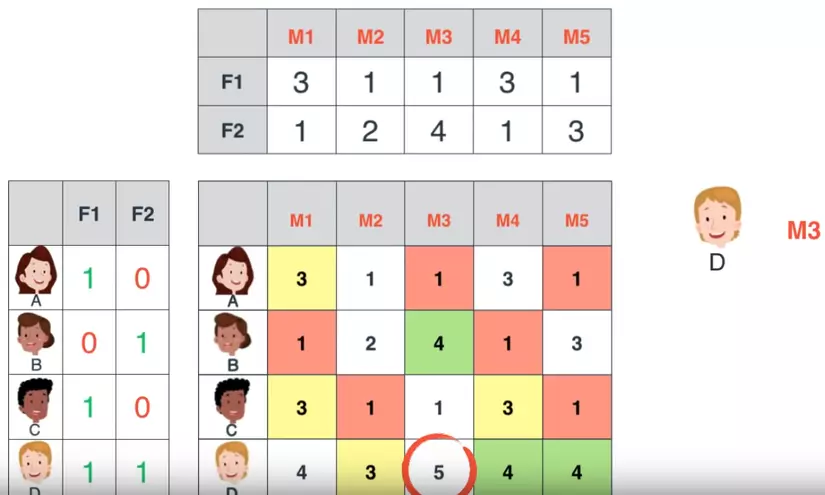
Hy vọng sẽ giúp bạn hiểu phần nào NMF. Cảm ơn mọi người (bow)
Không có nhận xét nào:
Đăng nhận xét