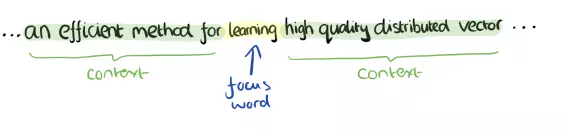
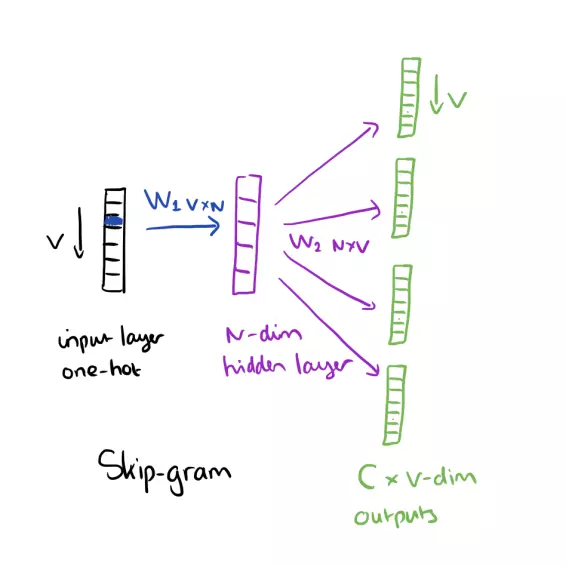
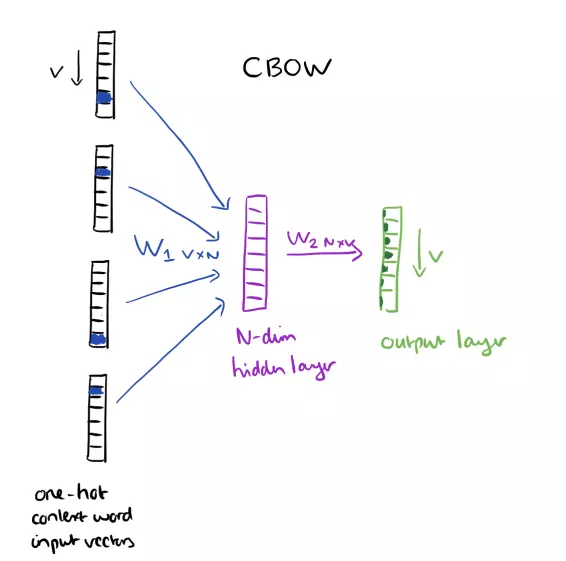
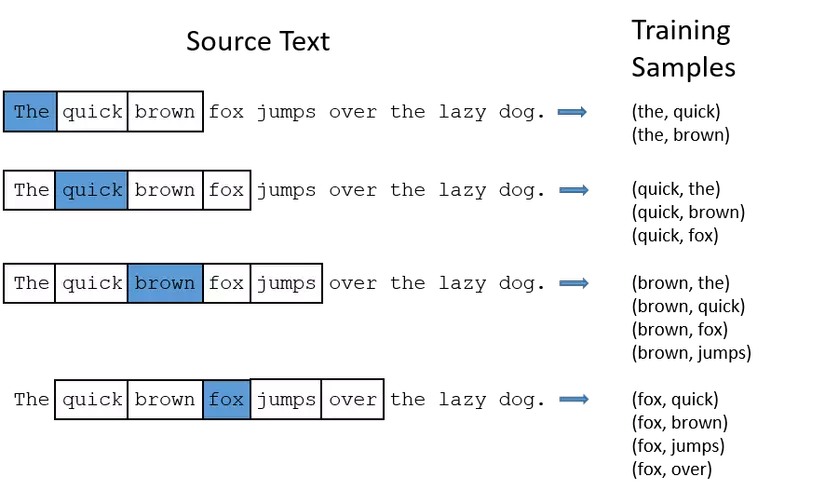
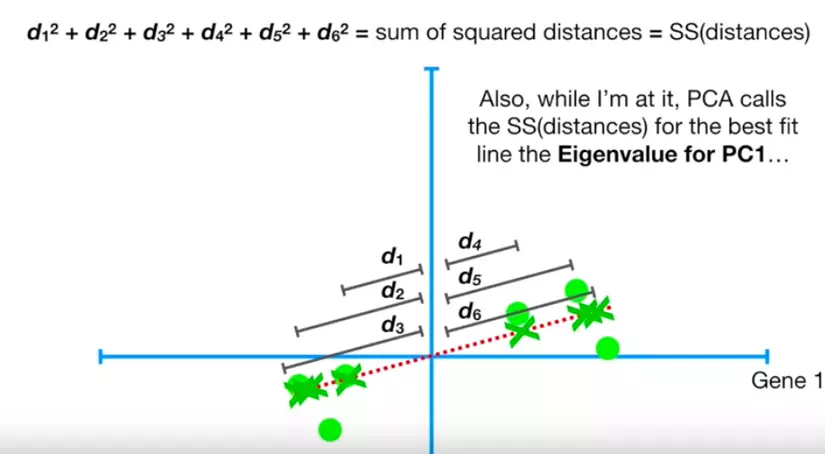
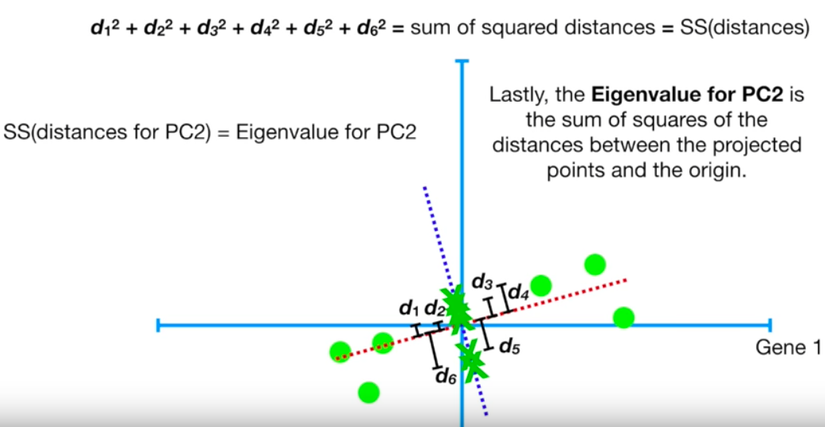
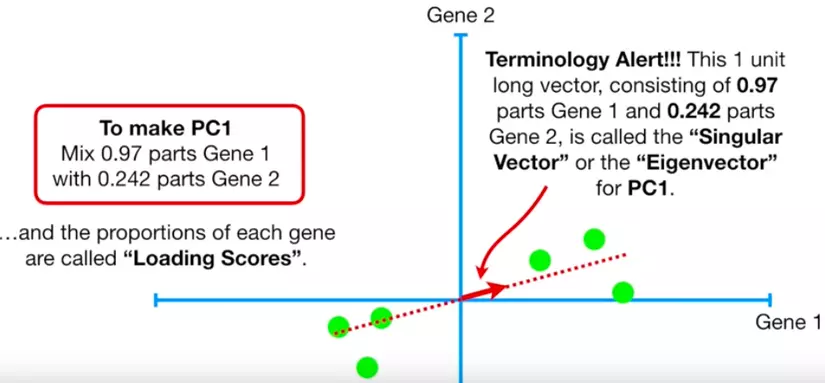
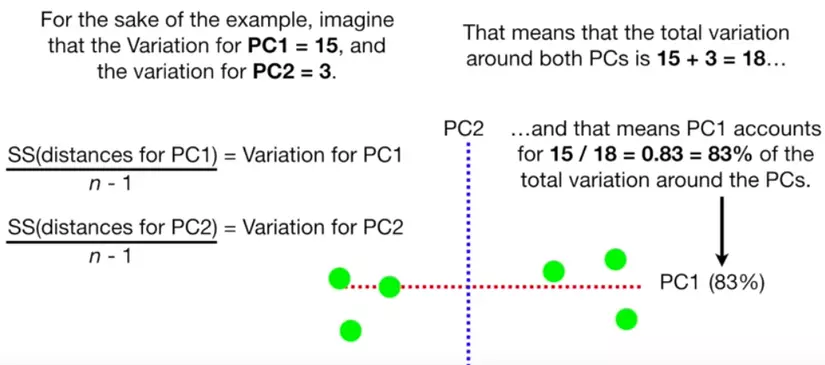
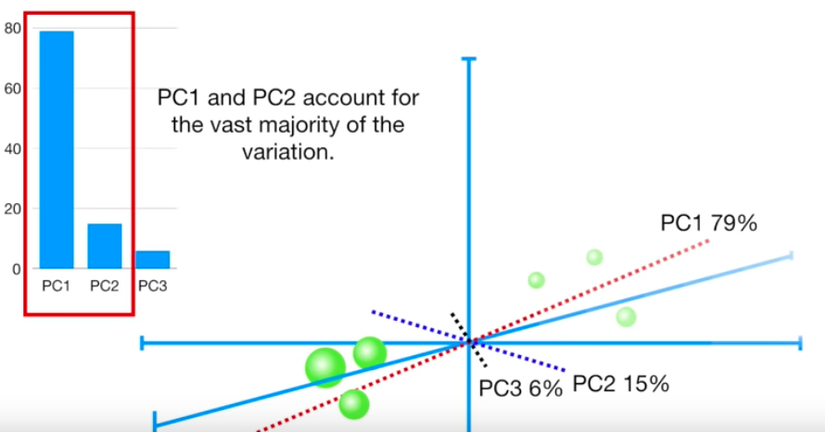
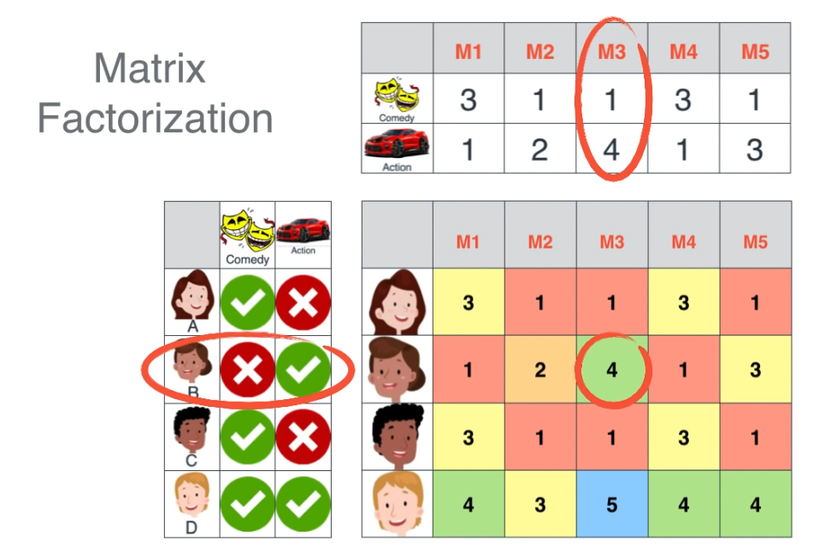
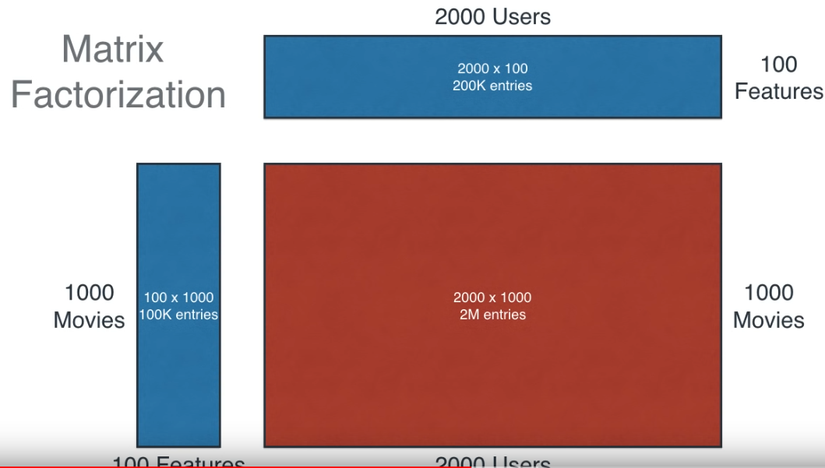
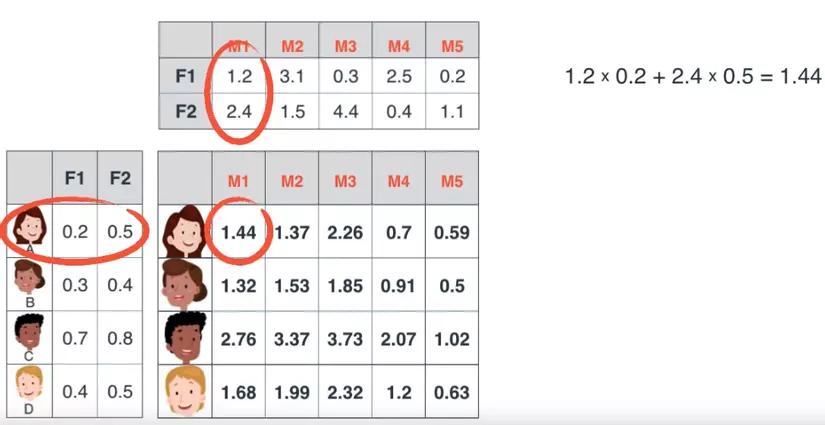
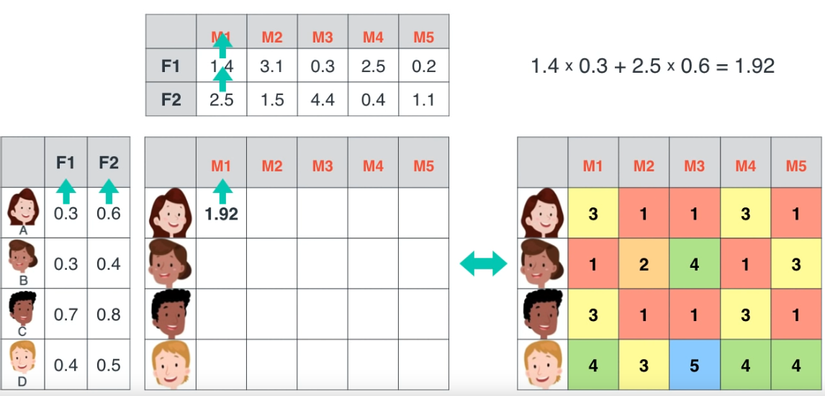
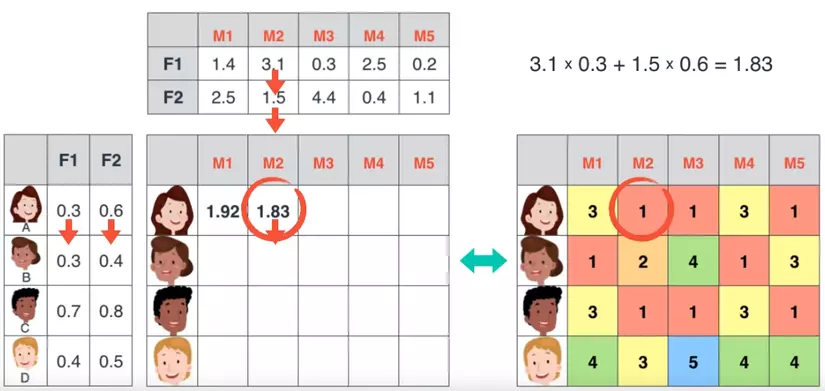
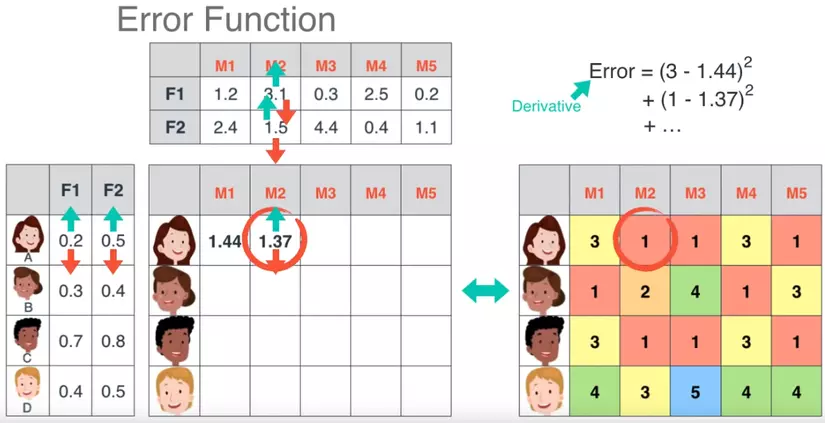
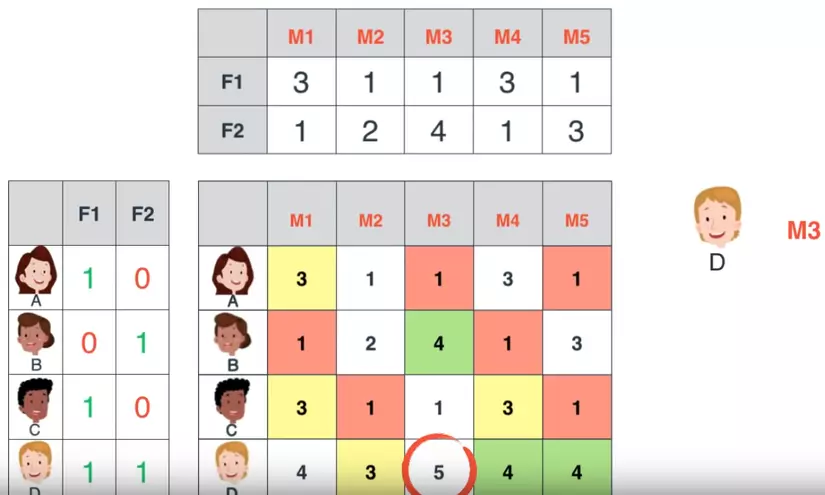
Đồ chơi.
The React Framework https://nextjs.org
- Bộ combo trọn gói mì ăn liền nextjs, hỗ trợ từ đầu đến đuôi, từ frontend tới backend, server side rendering.
- Mình sẽ làm thử một cái notebook cho việc ghi chú bằng thằng này :#).
Cấu trúc folder mình học được từ các cao nhân trên github.
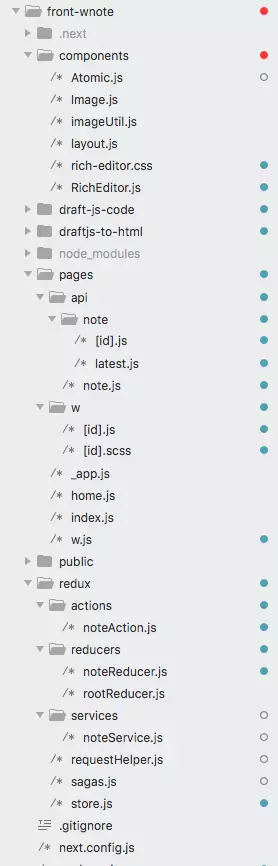
API thì chúng ta bỏ vào đây, code này wrapper express để chạy phía server, cách đặt tên thư mục và tên file sẽ quyết định đường dẫn nhé.
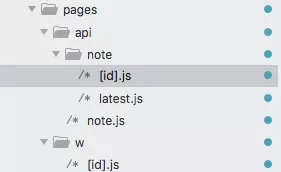
Như trên nó sẽ có đường dẫn /api/note/{noteID}.
Một số code index vào elasticsearch content gửi lên khakha :v
export default (req, res) => {
if (req.method === 'POST') {
const { id } = req.query;
client.index({
index: 'wnote',
id: id,
type: 'note',
body: req.body
},function(error, response, status) {
if (error){
console.log("index error: "+error)
} else {
res.statusCode = 200
res.setHeader('Content-Type', 'application/json')
try {
var body = JSON.parse(response.meta.request.params.body);
} catch (e) {
res.status(400).json('fail')
}
body = fnBuildResponse(id, body)
res.status(200).json(body)
}
});
} else if (req.method == 'GET') {
const { id } = req.query;
client.search({
index: 'wnote',
body: {
query: {
match: {_id: id}
},
}
},function(error, response, status) {
if (error){
console.log("index error: "+error)
} else {
res.statusCode = 200
res.setHeader('Content-Type', 'application/json')
res.status(200).json(response.body.hits)
}
});
}
}
Ở client cũng vậy, Router sẽ dựa vào cách mà bạn đặt tên file và thư mục.
Như trên bạn sẽ có đường dẫn ở client là http://localhost:3000/w/ba9d4acc-0fd4-4b75-8e71-4b581865cb29, tương ứng với thư mục w, và file [id].js, ở đây id = "ba9d....."
Về style ư, quá dễ dàng chỉ cần tạo file scss code ngon ăn rồi import vào file _app.js
import "./w/[id].scss";
import App from 'next/app';
import React from 'react';
class MyApp extends App {
....
}
Cách tương tác với redux , redux saga cũng giống như bình thường, chả có gì mới :#), nhờ vào package next-redux-wrapper, import vào và ăn liền, chẳng cần hiểu tại sao :v
_app.js
import "./w/[id].scss";
import App from 'next/app';
import {Provider} from 'react-redux';
import React from 'react';
import withRedux from "next-redux-wrapper";
import store from '../redux/store';
class MyApp extends App {
static async getInitialProps({Component, ctx}) {
const pageProps = Component.getInitialProps ? await Component.getInitialProps(ctx) : {};
//Anything returned here can be accessed by the client
return {pageProps: pageProps};
}
render() {
//pageProps that were returned from 'getInitialProps' are stored in the props i.e. pageprops
const {Component, pageProps, store} = this.props;
return (
<Provider store={store}>
<Component {...pageProps}/>
</Provider>
);
}
}
//makeStore function that returns a new store for every request
const makeStore = () => store;
//withRedux wrapper that passes the store to the App Component
export default withRedux(makeStore)(MyApp);
Show hàng:
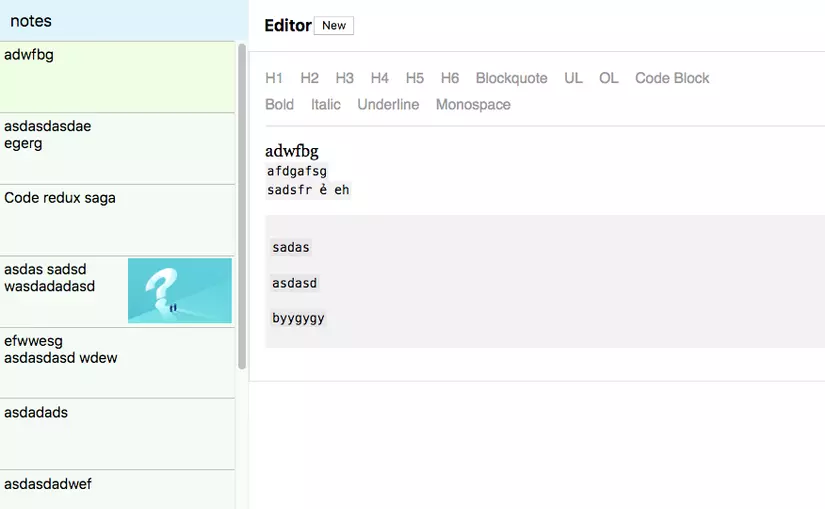
Quá nhẹ nhàng cho việc làm quen một framework ngon ăn